写给新生的高性能计算入门(一) —— 高性能计算国内外发展现状及发展趋势

说起超级计算机,大家应该会有一个概念,大致就是计算能力很强的计算机。甚至在某乎,还有人问 在超算上面打游戏是什么体验。 这里解释一下,实际上,由于超算系统的限制,很少能够可以连接互联网,而且远程连接网络性能也可能不好; 还有就是,游戏的程序并没有做大规模并行化(实际上也没必要),顶多只能单节点多核运行(可能还没GPU),所以打游戏的计算性能和单个普通服务器的性能差不多。对于超算来说,其强势主要在于计算能力(而且为了保证你的程序可以利用上超算的计算资源,需要针对超算环境去编写/改写并行程序,这个我们后面讨论并行编程的时候会讲)。
在高性能计算领域,有一个榜单 top500,该榜单每半年(6月份和11月份)公布一次世界上计算能力前500的超级计算机,其中6月份是在ISC(the International Supercomputing Conference)大会上公布,11月份是在SC(SuperComputing Conference)大会上公布。 该榜单最早由Hans Meuer、Erich Strohmaier与Jack Dongarra于1993年发起。
超算中的基本概念
节点(nodes)
简单来说,超算就是有很多计算节点,通过高速互联网络连接而成的计算机系统。每个节点实际上是一台比较独立的计算机,每个节点上可能会有多块 CPU 、加速计算硬件(如GPU、Intel phi等)、内存、操作系统(基本都是Linux系统)。
由于一个节点上,可能有多快CPU,每个CPU可能还是多核的,再加上加速卡,所以一般单节点都是一个具有多个核心的节点。
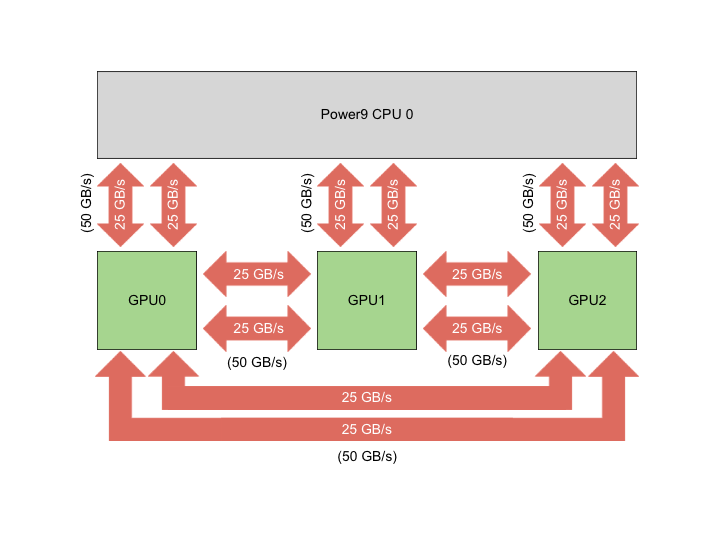
例如,目前(2019.09)排名 top500 第一的超算 summit,每个节点的结构如下图所示。其每个节点有一个 Power9 CPU,外加3块 NVIDIA V100 GPU。节点内部的 CPU-GPU 以及 GPU-GPU之间通过 NVIDIA NVLink 互联起来。
文件系统
一般地,超算上不是每个节点都有一块硬盘的,而是用的各个节点共享的并行文件系统,使用并行文件系统,各个节点都可以向这个共享的文件系统中写入或读取文件。
计算能力的衡量指标: FLOPS
FLOPS,或者叫 Flops、flops 或 flop/s,即 floating point operations per second, 指的是计算机系统每秒可以进行的浮点数操作次数, 具体可参见 wikipedia-FLOPS。 除了FLOPS作为单位外,还有 GFlops,TFlops,EFlops,ZFlops等单位,其中:
- 1 KFlops = 1000 Flops
- 1 MFlops = 1000 KFlops
- 1 GFlops = 1000 MFlops
- 1 TFlops = 1000 GFlops
- 1 PFlops = 1000 TFlops
- 1 EFlops = 1000 PFlops
- 1 ZFlops = 1000 EFlops
例如目前,无锡神威太湖之光超级计算机,其持续浮点性能为 93.0146 PFlops,9.3亿亿次/秒 (在 top500 网站上列出的超级计算机性能表里面,会提到系统的峰值性能(Rpeak)和持续性能(Rmax))。
Linpack 测试
如何测试一个超级计算机系统的浮点性能呢?目前 top500 采用的是 Linpack 基准测试(HPL, High-Performance Linpack Benckmark)。
Linpack benckmark 最早在 1993 年由Jack Dongarra 引入。
这个基准测试实际上是求解一个巨大的线性方程组。通过在超算系统上运行这个benckmark,就可以测试出超算系统的浮点计算能力。
2019 年 06 月份 top500 榜单
2019 年 06 月份的top500榜单在德国的ISC会议上公布,具体情况可以在 top500.org/lists/2019/06 看到。
榜单的前两名由美国的两台超算 Summit(顶点) 和 Sierra 占据。这两台超算均为IBM建造,采用Power 9 CPU + NVIDIA V100 GPU 的硬件,均安装在能源部下的橡树岭国家实验室(Oak Ridge National Laboratory)。
第三名为无锡的神威太湖之光超级计算机,2016-2017年top500排名第一,采用国产申威 SW26010 芯片( alpha 指令集)。
第四名的为位于广州超算中心的天河-2A超算,2013-2015年top500排名第一,2016-2017年top500排名第二。
值得注意的是,天河2号超级计算机在2018年有一次升级,使用自己的 Matrix-2000 加速卡替代了因特尔的 Xeon Phi 加速卡(由于受到美国禁运)。
后面排第5至10的超算,例如排名第8的日本富士通公司建造的ABCI超算,还有德国的SuperMUC-NG超算,基本都是采用Intel CPU或者Power CPU,加速卡(如果有的话)采用Xeon Phi 或英伟达 GPU。
在 top500.org 网站上,可以看到各个国家超算的treemap图(传送门),
按国家分类,2019年06月份的榜单,超算所属国家的treemap图如下所示。可以看到中美是两个超算大国,德国🇩🇪、日本🇯🇵也表现优异。

另外,我们还注意到,好多超算都使用来英伟达的GPU进行加速计算,也许这和近年来的人工智能热潮有一些关系。 基本上,很多超算都是CPU+加速卡/GPU混合的这种异构加速体系架构。
超算领域下一个角逐点: E级超算
事实上,无论是美国,还是欧洲、日本,或者是中国,都在发力E级超算。 E级超基本计算机已经称为各超算大国的下一个角逐点。
据美国能源部(DOE)网站2019/03/19日报道,能源部表示将拨款5亿美元给英特尔公司和克雷公司,以共同建造美国首台可实现每秒百亿亿次浮点运算的超级计算机(简称E级超算)“极光”(Aurora)。“极光”预计2021年交付,将主要用于推进科学研究,促进新发现。 美国能源部表示,“极光”将建在能源部下属的阿尔贡国家实验室内,目标是促进科学创新、引领新的技术能力,进一步提升美国在全球的科学领导地位。
引用新闻链接:美国能源部网站。

例如美国正在建造aurora,由Intel和Cray打造,预计2021年交付,将安装在阿贡实验室。
AMD也宣布联合Cray公司打造1.5Eflops计算能力的超级计算机Frontier,预计2021年交付给橡树岭国家实验室。
另外,美国Cray公司也宣布(2019年8月)获得美国能源部、国家核安全管理局价值6亿美元的新订单,将建造一台性能高达150亿亿次(1.5 exaflops)的超算 El Capitan,预计2022年底正式交付,主要用于核武器研究。
中国也已经完成来神威、天河、曙光等三套E级机等原型系统的研制。
可进一步了解:https://www.r-ccs.riken.jp/R-CCS-Symposium/2019/program.html 中的报告 "Tianhe-3 and the Exascale Road in China"。
欧盟预计于2022年—2023年交付首台E级超算;日本发展E级超算的“旗舰2020计划”由日本理化所主导,完成时间也设定在2020年。