先导杯参赛记

北京已经开始有冬天的寒意了,据说某些地方已经开始小雪了。 想起来,还是写点东西吧,以免以后忘了,算也是对这半年的工作做一个恰当的纪录吧。
(零)
先导杯到今年已经是第二届了,不过去年我们没有参赛,所以这次还是第一次参加。 当去年那时候,看别人拿奖、屠榜,说不眼馋是假的,作为一个技术宅,谁不想炫一下自己的技术呢? 而直接导致我想参加今年的赛事主要还是,因为受到昆山超算的一位工作人员的“鼓动”,让关注下第二届先导杯。
在4月份的某天,那时候天气还是暖洋洋的一片,先导杯公众号开始宣传第二届的时候,就已经开始跃跃欲试了。 没记错的话,这应该比我导转发相关比赛消息要早个几天的样子。 然后就问组内的同学是否有参加的意愿,开始准备组队和选择赛题。 经过讨论,我们都比较倾向于偏数值计算这块的内容,而对于 AI 赛道和量子计算赛题等,一方面不是我们的专长, 第二是我们做完后也难以反哺到课题组内部的研究中。 最后基本就在矩阵特征值和稀疏矩阵向量乘 (SpMV) 中选择,最终还是倾向于 SpMV 赛题, 主要原因还是因为这个题目比较好理解,就是在 GPU 上计算一个 CSR 格式的稀疏矩阵乘以稠密的向量, 而矩阵特征值的题目似乎有些看不太明白(如 Hermite 复矩阵、Householder 方法等),需要花些时间补下这块的数值计算方法。 接下来就是拉人组队、报名操作,一套行云流水的操作下来,拉了四五个小伙伴的队伍。
(壹:一鼓作气)
参赛之前,我们也会写 CUDA/HIP 程序,但是在深度优化方面却经验显得不够。 所以,一开始,就从师弟本科毕业设计里面做的稀疏矩阵向量乘法的代码开始慢慢挖掘,这部分比较简单,但是却为起步阶段提供了一个良好的开端。 逐渐尝试了一些简单的计算方法,如采用 block 计算一行,采用一个 wavefront 计算一行的等计算模式。 在另外一方面,也开始看一些现成的代码实现,最先看到的就是 AMD GPU 对应的官方实现—— rocSparse。 �实际上,rocSparse 也是类似的,融入了 “一个 wavefront 计算一行” 的策略。
在开赛一个月后,5 月 15 日,我们提交了第一个月度的代码,其主要采用前文 “一个 wavefront 计算一行” 的模式。 由于完全不知道对手的情况,所以对于自己代码的性能好坏也完全没有一个判断标准(虽然在比赛的算例上,确实会比系统的 rocSparse 库快一些)。
![]()
忐忑地等待了几天后,公布了5月份的排行榜单,第一?我们居然拿到了第一? 这对于我们也确实是很大的鼓舞,想着各队伍也就不过如此,轻松碾压。 但实际上,也确实高兴得太早了,风起云涌,好戏也才刚刚开始,后面的赛况才是跌宕起伏。
5月排名结束后,组委会改了两次赛题的算例,采用了 SuiteSparse Matrix Collection(https://sparse.tamu.edu) 中提供的10个算例, 且初赛仅测试10个算例中的一个叫 Hardesty3 的算例。 在此之前,采用的是固定的随机数生成的矩阵,这个算例确实不够接近实际情况,用 SuiteSparse 的算例确实会更恰当。 另外,恰好算例 Hardesty3 较为特殊,其平均每行的非零元素数才为 4.9,可以说特别稀疏了。 这种情形下的矩阵,必须想新的办法来计算,当然这是后话了(我们后面才体会到的)。
在6月份中,我们还是按照一起的思路,继续往下探索,参照现有的资料实现新的算法,叫 vector-row (也即相关文献中提到了 CSR-Vector 方法,其将 wavefront 划分为几个 vector,让每个 vector 计算一行), 做了几点访存相关的优化(带来性能明显提升的主要是一些访存连续化的优化),并改了下核函数配置。 在这期间,通过我们的分析判断,加上相关文献的印证,我们也逐渐意识到 SpMV 是一个关于访存优化为核心的问题。 至此,对于初赛的 Hardesty3 算例,能从 5 月份算法的 20000 多us,到原始 vector-row 算法的 2100 us,再到一系列优化后的 1704+ us, 我们自信心很满,觉得我们做了好几点优化,且都有一些优化效果,觉得这次保持第一问题不大。甚至,觉得这部分的工作完全可以写一篇较好的论文了。 然而打脸到事情来了,而且是打得巨疼的那种。
6月排名出来了(6月中旬提交代码,月下旬/月底出排名,这个月是6月28出的月度成绩),我们第五,第一名用时 1155 us,第二名也是 1170 us,比我们的 1704 us 快了不知道多少,直接惊掉我们双下巴😱。
![]()
对于 6 月这个排名,我们属实难以理解为啥别人会快那么多。 当时正在开组会,拿到6月的成绩后,就现场在组会参会的人员公布了。那是的心情可谓五味杂陈,与预期不符带来的落差感充满了整个身体。 虽然老师说,要迎难而上,要搞清楚 1155 是怎么来的,但别人的算法对于我们而已是不可知的。 不过,这个也确实是我们接下来的工作目标。我们也重整行装,又开始上路了。
(贰:再而衰)
1704 us -> 1250 us
那么,接下来的压力就大了一点,不过在心理上,倒没有胆怯或者望洋兴叹,我认为我们也可以拿到 1155。毕竟只要有信心��在就不会怕。 接下来的,我们也开启了两条路线。 第一种方案,是沿着我们的 vector-row 算法,继续优化。
我们在7月份,开始了 vector-row 的一些新的优化,主要包括 double-buffer 的数据预取和更强的数据 pipeline 预取。 前者能到达 1470 us,后者能到达 1413 us 左右。虽然时间相比 6 月的成绩有了明显的提升,但距离 1155 还是有不少的差距。 而且,更要命的是,这个方法难以再继续往下优化了,到了瓶颈了。这条路线,在7月初被彻底放弃。
这也就逼迫我们换新的算法。 至此,我们也开始着手研究其他的算法。站在巨人的肩膀上,那肯定得看看巨人何以成为巨人。 在出排名的第三天,7月29号,我继续以纯 CSR 格式在 GPU 上的计算优化为目标,差不多找了一圈相关的论文。
在之前已经搜罗了一遍的基础上,发现 SC14 顶会上的 [CSR-Stream][^1] 算法是我们所不掌握的。 紧接着,火速对论文中的算法进行了最基础的实现(我们实现的版本称为 "line" 算法),测完发现这个算法确实还可以,能到 1400 us。 我想,咱再接着优化优化,包括把前面的优化思想借鉴过来,说不定可以达到很不错的效果,甚至可以达到第一名他们的成绩呢。
整个7月初,都是完全沉浸在程序优化和算法上。例如,周末大半夜的测试 line 算法的访存开销。 事情的小转机发生在7月6号开始的这几天,队员发现通过适当调整核函数的线程数和 Block 数量配置,可以将 line 算法在初赛算例上的时间继续降低到 1330+ us 左右(甚至有时候还能碰巧跑到1270 多微秒)。 另一方面,为了进一步优化手上的算法,我们也开始深入了解 GPU 内部的硬件层面的东西,例如 GCN 架构、L1 cache的技术规格、GPU 内部的寄存器、汇编指令等等,还有内存通道冲突、HBM2 内存啥的��(不够像 Cache、HBM2 内存这些最终也没用上)。 对于我而言,这些几乎贯穿到了日常的吃饭、等电梯环节中。 这期间也坚持一周一次的小组会讨论,不过到了瓶颈期间,每人也提不出太好的改进建议。 https://github.com/senior-zero/matrix_format_performance
另一个新的火花发生在7月初的某个晚上(2021/7/7凌晨),想着目前的算法基本都是按行进行任务划分的,
咱们是不是也可以按照非零元素进行划分呢?在床上对着这点思路,就拿出 pad 慢慢理各种细节。
因为这里面,还有很多细节的地方没有考虑清楚,例如一行可能会被划分到多个 block 上,多个 block 如何将数据写回等;
为了让每个 block 知道自己算哪些数据,是不是还得给算法加上个预处理(不过预处理可以在 GPU 并行)。
最终,用一晚上的时间,把脑子中的那点火花变成了熊熊燃烧的火苗。
凌晨一点,将整理好的算法思路发到了讨论群里面:
 这个算法,被暂时命名为 liner 方法,不够最终在代码中,是用了 "flat" 这个名字。
这个算法,被暂时命名为 liner 方法,不够最终在代码中,是用了 "flat" 这个名字。
这里还有一段插曲,我们后面发现,这个算法的思想,在另外一篇 ICS 会议上(论文:HOLA[^2]), 被发表了😂,预处理的代码和我们的几乎一致,而核心的计算实现有点去区别。 (这应该是7月15以后的事情了,即7月份提交代码之后。) 不过,这篇论文也是我们 7月初搜罗的相关论文集里面的,只是那时候还没仔细研究这篇论文,只是走马观花的扫了下。 这种“撞车”的经历,属实有点可惜。不过往好的方面想,也算�是对我们研究的深度的一种 “变相” 的认可了。 当然,这都是后话了。
思考完了新的 flat 算法的思想的细节流程,第二天(也就是7号)就开始把这个算法实现出来了,再加上一些正确性测试,包括一些特殊情况的考虑, 到8号,我们就完成了 flat 算法的开发工作,合并到了代码仓库的主分支中。 不过,比较遗憾的是,flat 算法在初赛的这个算例上,表现并没有超过先前的 line 方法。 当然,flat 在其他的决赛的算例上,表现得还是很出色的。如果我们可以进入到决赛中,那么该算法一定会充分发挥其优势。
时间一晃,也差不多到了7月份提交的前夕了(15号提交)。
也就是在这 deadline 之前,突然转念一想,无论是 flat 还是 line,他们都是用到了共享内存,将访存从不连续变为了连续的。
突然脑子一抽,把之前给一个线程分配一行计算任务的这种计算模式搬了过来,再加上共享内存作为缓存,最终实现了一个船新版本的 thread-row 计算策略。
这个策略一测试,效果却相当可以。对于初赛的算例,运行时间能达到 1230 us 至 1280 us 之间。这或许就是前几名用到的方法吧。
这是一件很欢欣鼓舞的事件,这也意味着,我们经过接近一个月的努力,也算是赶上了很多(虽然还有一些差距)。
算例的运行时间从上个月的 1700+ us 降低到了 1250 us 左右。
这时,也差不多到了提交本月度成绩的日子,我们将我们的 thread-row 算法的代码及相关文档,整理提交了。
但心里却总是有些忐忑...
(叁:似乎进不了决赛了)
1250 -> 1240 us
我们将7月份提交的代码发布为 v0.3.0 版本,该版本包括了 line、flat、thread-row 三种新的计算策略。 虽然我们整个7月度的优化工作取得了不错的进展,有三种新的算法出现,但是很遗憾,却始终没有搞清楚第一名 1155 是如何达到的。
7 月 20号左右,郑州暴雨⛈️。而我们比赛测试的机器也正好在郑州,机器的主供电系统受到暴雨影响,系统关闭。 而也是这一几天,举办方也才测试了部分队伍的性能成绩。我们队伍在20号核对的我们自己的成绩是 1254 us(和我们自测的差不多),但尚不知道排名。
我们这边在系统关闭期间也转移到昆山的机器上继续测试。但是进展不大,仅限于修改一些参数,无本质进展。这期间我们主要还是为了优化进决赛后的一些算法和代码。
终于,我们在8月9号左右等到了上个月度的成绩排名。同时因为暴雨,组委会也宣布了比赛后延。
第二届“大奖赛”受7月郑州大雨的影响(比赛环境部署在郑州,有2周多无法使用),致使比赛受阻,特将初赛延期至8月31日截止。 同时,为了给选手提供充裕的时间做优化,收获更好的比赛成果,计划于10月中旬举办决赛。
这次我们的排名比较离谱,榜上无名。虽然我们队伍有进步(排第七名),单耐不住别人比我们进步更明显。 甚至还被导师调侃道“怎么越来越往后了呀”(原话)。当时我趁着暑假回家了一趟,大晚上在家直接给整失眠,而且不是一天,是接连一两周。 前面像flat 这些为了决算算例而设计的算法的优化工作基本都可以停下了,需要全身心的回归到初赛算例上来,不然怕是会直接在初赛阶段淘汰掉了。 虽然发动了队伍的所有人员一块加油干,而且7/20号左右我也进行了一些初赛算例的优化(关于x 向量访存连续到优化),能将性能搞到 1240/1232/1239 us 的样子,似乎比7月份提交的要稍微好一点。但是似乎进步不大,距离前面仍然差距不小。
![]()
(肆:8月)
1240 us -> 1160 us
八月的烈日炙烤着大地,北京城市的夏天更是燥热。电脑的风扇飞快的转着,似乎房间的热量更多了。
在8/10号,我把初赛算的代码的另一个版本提交到了git 仓库(原先是eavefront 划分,现在换成block 级的划分)。并特别提到这个新代码不优化能到1250us,加上前面的一些优化应该会好不少。接着一周时间便让师弟帮忙把之前到优化技巧给加到新版本里面。后面测了下,能达到1205-1230 us 之间。这个时候已经是17号了,距离结束也就十几天了。考虑到其他队伍的进步,我们目前的代码进决赛还是完全没把握,这样子底性能大概率是要被淘汰了(后来的初赛成绩也验证了这个性能进不了决赛)。
(20号还有个小插曲,闹了次乌龙,由于校验的bug,某次改完代码跑出来1050us,还给高兴坏了,结果排查出来又是满满的失望。(甚至还开玩笑说要不要用这个bug作弊)
23号,把最后一个优化点迁移到了新版本初赛算法上 (block 级的 x 向量 remap)。平均时间从1230-1250 降到了1215 左右。这个优化确实比较复杂,因此花费了一些时间完成。
想着这大概就是我们的极限水平了,前面1160us 的是咋优化出来的��,也只能望洋兴叹了。 虽然比上个月度排名好了不少,但是心里仍然没底——关于能否进入决赛的底。前程全是问号,这样子能到决赛吗?(后来的初赛成绩来看,这个性能还是进不了决赛)
没想到事情还能迎来反击的机会,就是在提交结果的前两天,29、30号,我将核函数参数设置成一个block 只计算一轮。没想到竟然能跑到1160-1170us 之间。甚至快一点的情况,还有1144us的情况。(因为这样计算和访存重叠性更好) 这大概就是喜极而泣的感觉吧,这下决赛进去大概99%稳了。 后面一两天就是整理下代码和文档,提交了初赛的代码,静等结果。
(伍:决赛了)
在等待初赛结果的这几天内,我们继续讨论、沟通、coding以及布置任务。 优化方面,主要集中在 flat 算法的 reduce 的优化上(结果写回部分的访存优化)。 九月初,我还把 HOLA 的代码移植到了我们的 ROCm 计算平台上,也简单测了下,发现我们的 flat 比他们的要好。
9月6号,我们的初赛算例 Hardesty3 的组委会测试结果出来了,一开始测的是 1182 us,比我们自己测的偏高。后面我们申请了重新测,最终性能定在了 1175 us。
三天后,也就是9号,组委会公布了进入决赛的名单,取前8名,但是没给排名和各队伍的成绩。我们的队伍是在名单里面的,也算是意料之中吧。
我们稍微讨论了这次的排名数据,发现一个有意识的情况,7月排名的第四名(成绩为1216us),竟然在决赛名单里面。
也就是说,1216 us 的成绩是进不了决赛的。而我们,在初赛提交前几天,成绩还是只能到 1215 左右,最后两天才优化出 1170 us 多的性能,可以说是很险了。
另外,决赛的代码提交,初步定在了 10月7 号,也就是国庆节结束的时候。此时,我们还剩一个月的时候优化我们的算法。
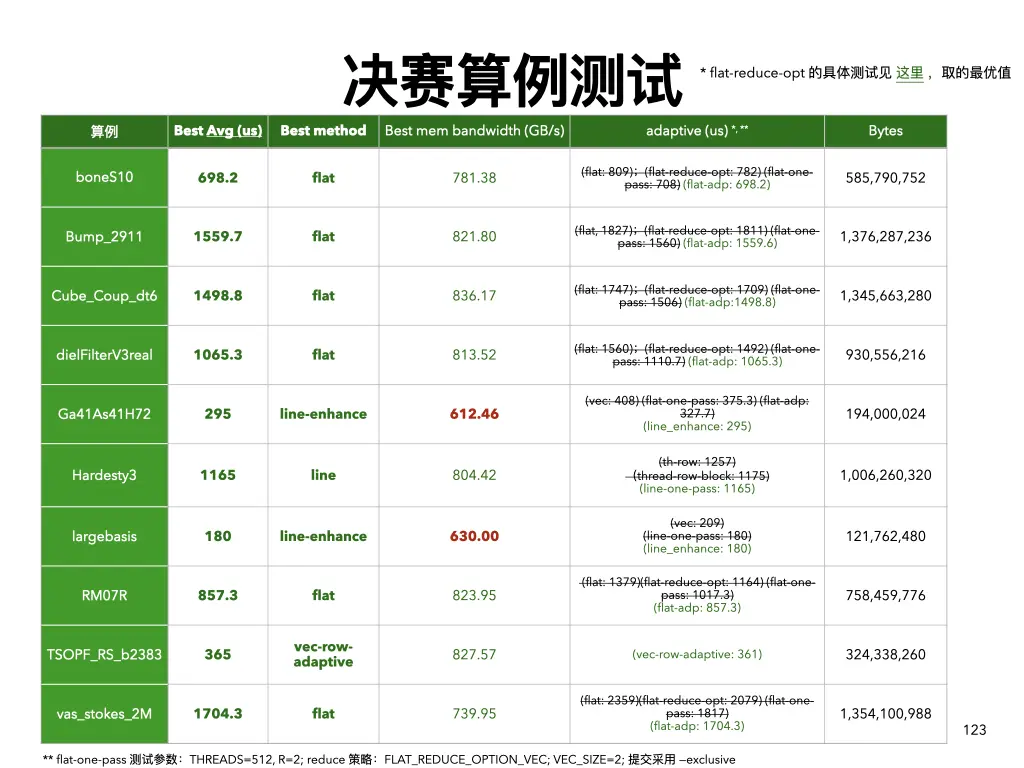
这里,需要提一下,决赛有 10 个 test cases,他们的矩阵特征和初赛的不太一致,所以对符合这些特征的矩阵,需要重新设计算法,最后用一个 adaptive 的方式来做算法选择。因此,这后面一个月,我们基本都在优化决赛的算例对应的算法上了。
对了,还有修复我们算法中的某些 bug,其中,最直接纪念的就是一个关于 synctreads()相关的用法的问题了,为此我还专门写了篇博客。
到了现在这个阶段,我们衡量算法的性能,不能光看时间(毕竟初赛看时间,还是有对比其他的对象的), 我们目前主要采用访存带宽来作为性能带衡量指标,看我们的算法能利用到多大的访存带宽,离理论的上限还差多少? 我们想让我们的这10个算例,都能达到 700 GB/s 的访存带宽,最好能冲到 800 GB/s 以上。
9/13号左右,我们借鉴初赛的思想,对 flat 算法开展了 one-pass 优化,即让一个block 只计算一轮。
最终的效果见下图,性能还是有很明显的提高的。例如 dielFilterV3real 算例,能从原先的接近 1500 us,降到 1110 us,
时间足足下降了进 400 us。
往后一周,我们基本就觉得没啥进一步的优化方向了,又陷入了死灵感枯竭的地步。 此外,很离谱的是,Ga这个算例,性能怎么都上不上去,也没啥好的方案,甚至只能用最基础的 vector-row 算法(即各种文献里面提到的 CSR-Vector)。 这可能是由于该矩阵特别不规则的原因吧,最终只能让师妹看下,能否调整下核函数的配置,看下能否有一些性能提高。 largebasis 这个算例,性能也很差,这主要是因为这个矩阵比较小,没法把性能撑起来。
这期间,我就重写了读文件的前端(因为读文件太耗费时间了),优化了下,当然这个不算入 SpMV的性能,只是为了方便我们测试(这一句算是流水账记录吧)。
一晃到了这个月的中旬,18号,我们开了个小讨论,技术上,主要还是看下 flat 算法能否进一步优化(如预处理优化等); 同时,也考虑测试下 flat 算法对应不同算例的最优参数。 同时,感觉也该写文档了(毕竟文档和最终的答辩分数占比 20%),就讨论了文档撰写的分工。
10/7优化截止, 10/14 ppt答辩,10/13号ppt提交。
18后往后的一周,我们基本都在准备文档。
在程序性能上的优化的进一步提高,是在 9 月底了。
29、30号,师弟说他写了个用 one-pass 思路方法的 CSR-Stream 算法的实现,再配合之前的一些优化技巧(如一次load两个数据,调整核函数配置和算法参数等),
针对 Hardesty3 算例,性能也还不错。特别地,对于 largebasis 算例,打破了之前的最好成绩的记录。
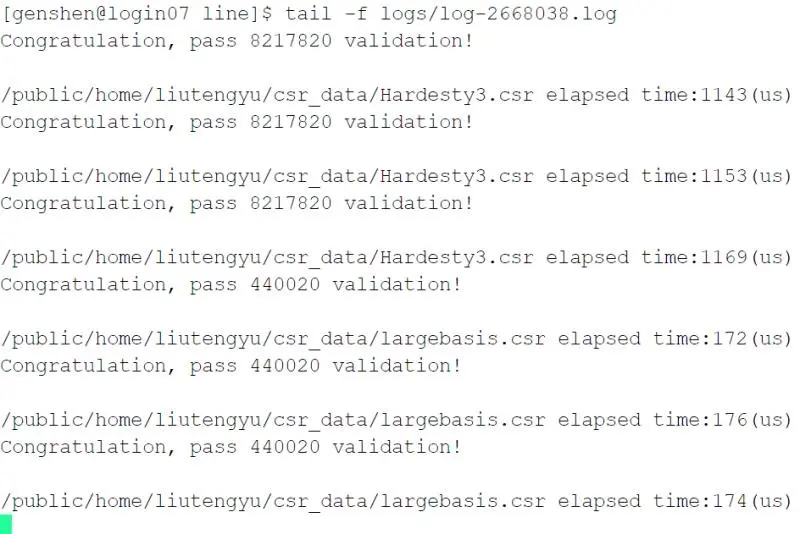
我们将这个代码优化整理了下,转眼就进入到了国庆假期了,离 deadline 也就七天的距离了。 最后,想着是否还可以冲刺一下,是否会有新的、更好的算法或者优化方法。
参考文献:
[^1] CSR-Stream: Greathouse J L, Daga M. Efficient Sparse Matrix-Vector Multiplication on GPUs Using the CSR Storage Format [C]//SC14: International Conference for High Performance Computing, Networking, Storage and Analysis. New Orleans, LA, USA, IEEE, 2014 : 769–780.
[^2] HOLA: STEINBERGER M, ZAYER R, SEIDEL H-P. Globally Homogeneous, Locally Adaptive Sparse Matrix-Vector Multiplication on the GPU[C/OL]//Proceedings of the International Conference on Supercomputing - ICS ’17. Chicago, Illinois: ACM Press, 2017: 1–11[2021–07–12]. http://dl.acm.org/citation.cfm?doid=3079079.3079086. DOI:https://10.1145/3079079.3079086.